
What is Synthetic Data and Why Does the Future Need it
There will be a slew of new technical terms and concepts that will come to the forefront in 2023, but probably hidden under the rubble is the term that will underpin many of these new technical terms and concepts - it's called synthetic data.
As the saying now goes, "Data is new Oil" and a few firms have an almost unlimited supply of it. To circumvent this monopoly, many firms are producing their own fuel, which is both cheap and efficient - Enter "Synthetic data".
What the Heck is "Synthetic Data"?
In place of real-world data, computer simulations or algorithms produce synthetic data, which is annotated information. To put it another way, Synthetic data is manufactured in the digital realm using computer simulations, algorithms, basic rules, statistical modeling, simulation, and other approaches. It is a substitute to real-world data, yet it mathematically and statistically mirrors real-world data.
Research shows that it can be just as good—if not better—than data collected on actual things, events, or people—for training an AI model. In fact, a field review identifies the use of synthetic data as "one of the most promising general techniques on the rise in contemporary deep learning, notably computer vision," which depends on unstructured data like photos and video. The report concludes that "many more possible use cases still remain" and that "synthetic data is crucial for ongoing advancement of deep learning."
The emergence of synthetic data coincides with the call of AI pioneer Andrew Ng for a sweeping change to a more data-centric approach to machine learning. In his newsletter, he suggests that, “Most benchmarks provide a fixed set of data and invite researchers to iterate on the code … perhaps it’s time to hold the code fixed and invite researchers to improve the data,”.
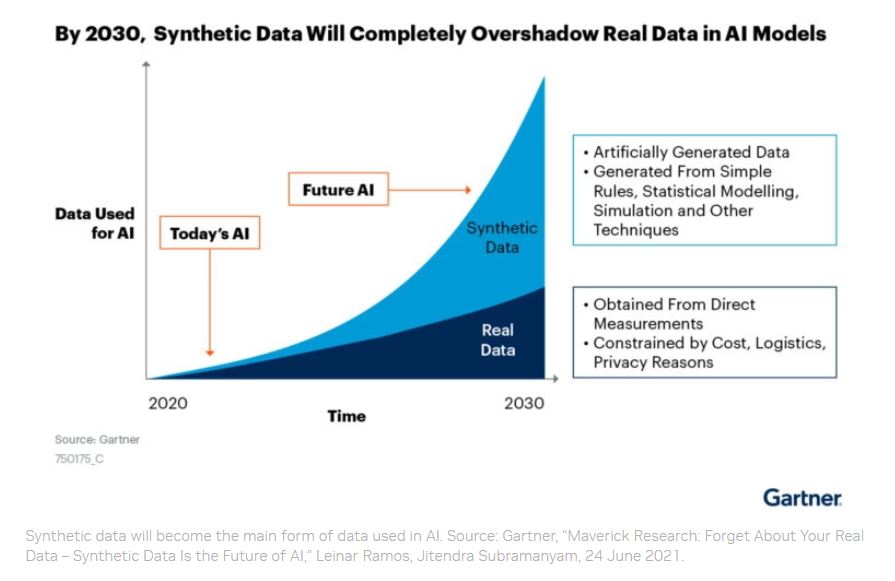
Furthermore, By 2030, most of the data used in AI will be generated artificially via rules, statistical models, simulations, or other methods, according to a report on synthetic data by Gartner. “The fact is you won’t be able to build high-quality, high-value AI models without synthetic data,” the report said.
Is Anyone Using Synthetic Data?
Today, synthetic data is used by car manufacturers, banks, drones, factories, hospitals, shops, robots, and the list goes on. Here are a few examples:
BMW - BMW used NVIDIA Omniverse, a simulation platform that enables businesses to engage using a variety of tools, to build a virtual factory in order to optimize the way it builds automobiles. BMW gathers data that is used to fine-tune how assembly both humans and robots collaborate to build automobiles effectively.
Amazon & PepsiCo - Amazon Robotics trains robots to recognize boxes of numerous sorts and sizes in logistics using synthetic data. The multinational food and beverage company PepsiCo utilizes synthetic data that it then uses to train AI models in NVIDIA TAO, improving the efficiency of its operations.
Why is Synthetic Data important?
Two Reasons: AI needs Data & Cost Savings.
To train neural networks, developers require vast, meticulously annotated datasets. AI models are typically more accurate when they have more varied training data. Whilst ChatGPT is great to play around with and possibly write some essays, it and other AI driven applications need continuous feeds of data. As such, synthetic datasets are superior to real-world data because they are automatically labeled and can purposefully include uncommon but important corner instances.
Paul Walborsky, who co-founded one of the first specialized synthetic data providers, says that a single image that may cost $6 from a labeling service can be synthetically generated for six cents. Saving money is just the beginning. By providing consumers with a diverse set of data that accurately represents the real world, synthetic data can address privacy concerns and lessen bias.
Should we only use Synthetic data then?
In fact, some experts claim that when it comes to training AI models, synthetic data is preferable than data from actual people, places, and things. Datasets may be adapted to specific circumstances that might otherwise be impossible to get, insights can be gleaned much more rapidly, and training is less time-consuming and far more successful. These limitations on using sensitive and controlled data are removed or decreased.
Synthetic data can have some potential inherent problems with it. One problem is that the synthesized data may not adequately reflect the occurrence in the actual world that it is meant to depict. This can cause the model to produce erroneous findings. Furthermore, the generated synthetic data may be skewed or erroneous if the model was built on a poor or biased dataset. Because of this, generated data does have the potential to enhance the training of AI models, but caution is required to fully exploit this potential.
Key Takeaways:
1. Synthetic Data will become the go to data in the future
2. Both Real world and Synthetic data will continue to evolve - keeping each other in check
3. Businesses will likely gravitate to more Synthetic data usage and possibly validate using real world data.
0 Comments